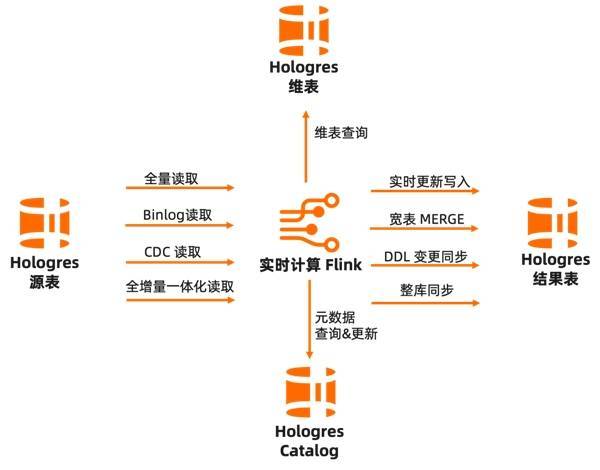
典型应用场景阿里云 Flink 与 Hologres 深度集成,助力企业快速构建一站式实时数仓: ● 可通过阿里云 Flink 实时写入 Hologres,高性能写入与更新,数据写入即可见,无延迟,满足实时数仓高性能低延迟写入需求; ● 可通过阿里云 Flink 的全量读取、Binlog 读取、CDC 读取、全增量一体化等多种方式,读取 Hologres 源表数据,无需额外组件,统一计算和存储,加速数据流转效率; ● 可通过阿里云 Flink 读取 Hologres 维表,助力高性能维表关联、数据打宽等多种应用场景; ● 阿里云 Flink 与 Hologres 元数据打通,通过 Hologres Catalog,实现元数据自动发现,极大提升作业开发效率和正确性。
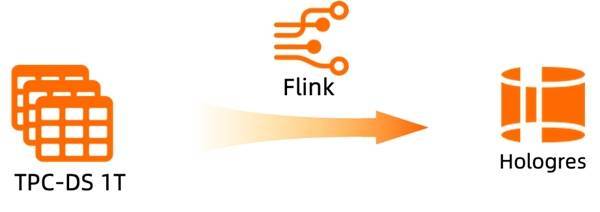
通过阿里云 Flink 与 Hologres 的实时数仓标准解决方案,能够支撑多种实时数仓应用场景,如实时推荐、实时风控等,满足企业的实时分析需求。下面我们将会介绍阿里云 Flink + Hologres 的典型应用场景,助力业务更加高效的搭建实时数仓。 4.1 海量数据实时入仓 实时数仓搭建的第一步便是海量数据的实时入仓,基于阿里云 Flink CDC 可以简单高效地将海量数据同步到实时数仓中,并能将增量数据以及表结构变更实时同步到数仓中。而整个流程只需在阿里云 Flink 上定义一条 CREATE DATABASE AS DATABASE 的 SQL 即可(详细步骤可参考实时入仓快速入门[4])。经测试,对于 MySQL 中的 TPC-DS 1T 数据集,使用阿里云 Flink 64 并发,只需 5 小时便能完全同步到 Hologres,TPS 约 30 万条/秒。在增量 Binlog 同步阶段,使用阿里云 Flink 单并发,同步性能达到 10 万条/秒。
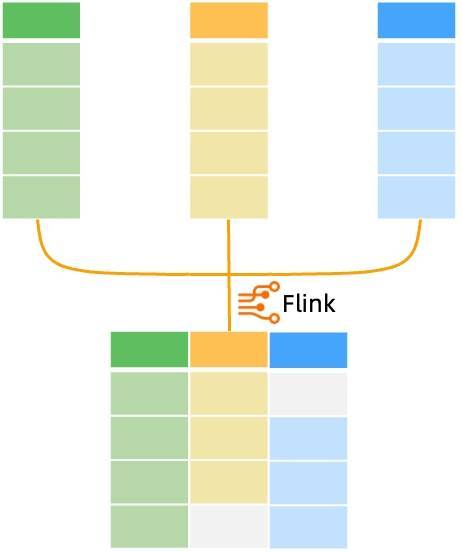
4.2 双流 Join 数据实时入仓形成了 ODS 层的数据后,通常需要将事实数据与维度数据利用 Flink 多流 Join 的能力实时地打平成宽表,结合 Hologres 宽表极佳的多维分析性能,助力上层业务查询提速。阿里云 Flink 支持以全增量一体化的模式读取 Hologres 表,即先读取全量数据再平滑切换到读取 CDC 数据,整个过程保证数据的不重不丢。因此基于阿里云 Flink 可以非常方便地实时加工和打宽 Hologres 的 ODS 层数据,完成 DWD 层的宽表模型构建。
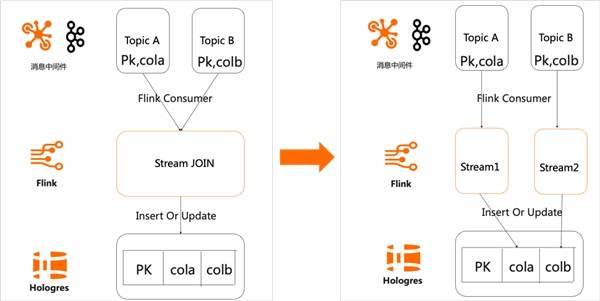
4.3 宽表 Merge 数据仓库中我们通常需要关心的就是建模,数据模型通常分为四种:宽表模型、星型模型、雪花模型、星座模型(Hologres 均支持),在这里我们重点要提到的是宽表模型的建设。宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。 宽表建设通常的做法就是通过阿里云 Flink 的双流 Join 来实现,包括 Regular Join,Interval Join,Temporal Join。对于主键关联的场景(即 Join 条件分别是两条流的主键),我们可以将 Join 的工作下沉到 Hologres 去做,通过 Hologres 的局部更新功能来实现宽表 Merge,从而省去了 Flink Join 的状态维护成本。比如广告场景中,一个 Flink 任务处理广告曝光数据流,统计每个产品的曝光量,以产品 ID 作为主键,更新到产品指标宽表中。同时,另一个 Flink 任务处理广告点击数据流,统计每个产品的点击量,也以产品 ID 作为主键,更新到产品指标宽表中。整个过程不需要进行双流 Join,最终 Hologres 会自己完成整行数据的组装。基于得到的产品指标宽表,用户可以方便地在 Hologres 进行广告营销的分析,例如计算产品的 CTR=点击数/曝光数。下图和代码示例展示了如何从双流 Join 改为宽表 Merge。
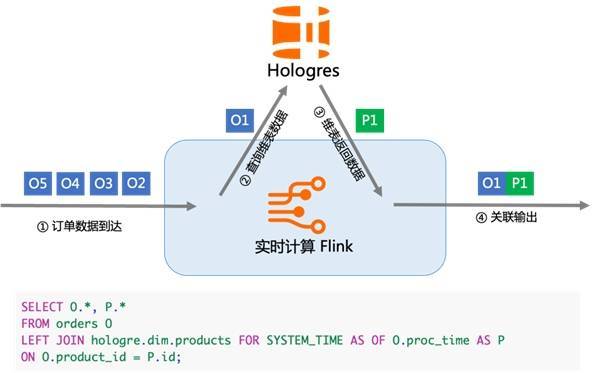
CREATE TABLE ods_ad_click ( product_id INT, click_id BIGINT, click_time TIMESTAMP ) WITH ('connector'='datahub', 'topic'='..'); CREATE TABLE ods_ad_impressions ( product_id INT, imp_id BIGINT, imp_time TIMESTAMP ) WITH ('connector'='datahub', 'topic'='..'); CREATE TABLE dws_ad_product ( product_id INT, click_cnt BIGINT, imp_cnt BIGINT, PRIMARY KEY (product_id) NOT ENFORCED ) WITH ('connector'='hologres','insertOrUpdate'='true'); INSERT INTO dws_ad_product (product_id, click_cnt) SELECT product_id, COUNT(click_id) as click_cnt FROM ods_ad_click GROUP BY product_id; INSERT INTO dws_ad_product (product_id, imp_cnt) SELECT product_id, COUNT(imp_id) AS imp_cnt FROM ods_ad_impressions GROUP BY product_id; 使用 Hologres 宽表的 Merge 能力,不仅可以提升流作业的开发效率,还能减少流作业所需要的资源消耗,也能够更容易的维护各个流作业,让作业之间不会相互影响。但需要注意的是,宽表 Merge 仅限于使用在主键关联的场景,并不适用于数仓中常见的星型模型和雪花模型,所以在大部分场景仍需使用 Flink 的双流 Join 来完成宽表建模。 4.4 实时维表 Lookup 在实时数仓中,在构建 DWD 层的数据过程中,一般都是通过阿里云 Flink 来读取消息队列比如 Datahub 上的 ODS 数据,同时需要关联维表来形成 DWD 层。在阿里云 Flink 的计算过程中,需要高效的读取维表的能力,Hologres 可以通过高 QPS 低延迟的点查能力来满足实现这类场景需求。比如我们需要通过 ODS 的数据去 Join 维表形成 DWD 层的时候,就可以利用 Hologres 提供的点查能力,在该模式中,通常使用行存表的主键点查模式提高维表的 Lookup 效率。具体的实现类似如下:
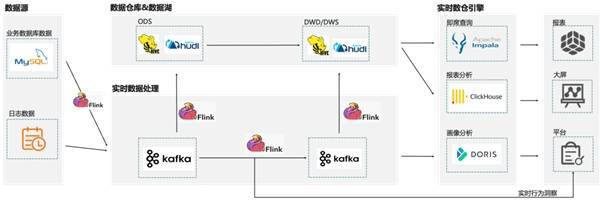
典型用户案例依托阿里云 Flink+Hologres 解决方案,企业可以快速构建一站式实时数仓,助力实时推荐、实时风控、实时大屏等多种业务场景,实现对数据的快速处理,极速探索查询。目前该方案已在阿里巴巴内部、众多云上企业生产落地,成为实时数仓的最佳解决方案之一。 以某知名全球 TOP20 游戏公司业务为例,其通过阿里云 Flink+Hologres 实时数仓方案,替换开源 Flink+Presto+HBase+ClickHouse 架构,简化数据处理链路、统一数仓架构、统一存储、查询性能提升 100%甚至更多,完美支撑数据分析、广告投放、实时决策等多个场景,助力业务快速增长。 5.1 业务困难:ETL 链路复杂、OLAP 查询慢 客户原数仓架构使用全套开源组件,架构图如下。其中开源 Flink 做 ETL 处理,处理后写入 ClickHouse、Starocks 等 OLAP 引擎。
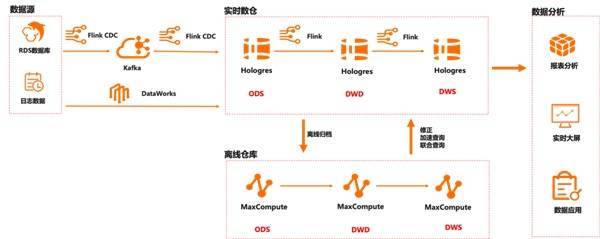
这套架构遇见的主要痛点有: 1、ETL 链路复杂 ● 为了解决数据实时 ETL,客户通过 Flink CDC + Hudi 做流批一体。但由于上游业务数据经常变更表结构,而开源 Flink CDC 缺乏 Schema Evolution 的能力,每次表结构变更都需要任务重新启动,操作非常麻烦,浪费大量开发时间。 ● Hudi 的查询性能不满足业务需求,还需要再加一个 Presto 做加速查询,造成链路冗余。 2、OLAP 架构冗余,查询慢 客户主要是靠买量发行作为游戏推广的重要手段,为了解决广告归因的实时决策场景对查询加速的需要,于是部署了开源 Presto、ClickHouse、HBase 等多套集群搭建混合 OLAP 平台。带来的问题有: ● 平台需要维护多套集群,导致运维变得非常复杂。 ● 开发需要在各种 SQL 中切换,为开发团队带来了许多困扰。 ● 由于 ClickHouse 缺乏主键,在归因分析时需要使用 Last Click 模型,带来了大量的额外工作。 ● 同时 OLAP 引擎的查询性能没有办法很好的满足业务需求,没办法根据数据实时决策。 ● 数据需要在多个 OLAP 系统中存储,造成存储冗余,导致成本压力剧增。 基于上面的痛点,客户开始重新做技术选型,并使用阿里云 Flink+Hologres 来替换现有的开源数仓架构。 5.2 架构升级:阿里云 Flink+Hologres 统一数据存储与服务 通过阿里云 Flink+Hologres 替换后的数据链路如下: ● 数据源数据通过 Flink CDC 能力写入 Kafka 做前置清洗,清洗后通过阿里云 Flink 进行 ETL 处理。 ● 阿里云 Flink 经过 ETL 后的数据实时写入 Hologres,通过 Hologres 替换了 Kafka 作为实时数仓的中间数据层,统一了流批存储。 ● 在 Hologres 中根据 ODS > DWD > DWS 层汇总加工。在 ODS 层,阿里云 Flink 订阅 Hologres Binlog,计算后写入 Hologres DWD 层,DWD 层在 Hologres 中汇总成 DWS 层,最后 DWS 对接上层报表和数据服务等业务。 ● 为了存储的统一,也将原离线 Hive 数据替换成阿里云 MaxCompute,以 MaxCompute 为离线主要链路。因 Hologres 与 MaxCompute 的高效互通能力,Hologres 通过外表离线加速查询 MaxCompute,并将历史数据定期归档至 MaxCompute。
5.3 业务收益:架构统一,性能提升 100% 通过架构升级后,客户的显著业务收益如下: ● 依托阿里云 Flink+Hologres,数据可以实时写入 Hologres,写入即可见,并且 Hologres 有主键,能够支撑高性能的写入更新能力,百万级更新毫秒级延迟。 ● 阿里云 Flink 提供 Schema Evolution 的能力,自动感知上游表结构变更并同步 Hologres,改造后的实时 ETL 链路通过订阅 Hologres Binlog 日志来完成,降低链路维护成本。 ● 通过 Hologres 统一了数据查询出口,经过客户实测,Hologres 可以达到毫秒级延迟,相比开源 ClickHouse 性能提升 100%甚至更多,JOIN 查询性能快 10 倍。 ● 升级后数仓架构变得更加灵活简洁,统一了存储,只需要一套系统就能满足业务需求,降低运维压力和运维成本。 |