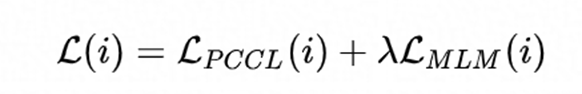如上图,CP-Tuning算法放弃了经典算法中以“[MASK]”字符对应预训练模型MLM Head的预测输出作为分类依据,而是参考对比学习的思路,将句子通过预训练模型后,以“[MASK]”字符通过预训练模型后的连续化表征作为features。在小样本任务的训练阶段,训练目标为最小化同类样本features的组内距离,最大化非同类样本的组间距离。在上图中,[OMSK]即为我们所用于分类的“[MASK]”字符,其优化的features表示为[EMB]。因此,CP-Tuning算法不需要定义分类的标签词。在输入侧,除了输入文本和[OMSK],我们还加入了模版的字符[PRO]。与经典算法不同,由于CP-Tuning不需要学习模版和标签词之间的对应,我们直接将[PRO]初始化为任务无关的模版,例如“it is”。在模型训练过程中,[PRO]的表示可以在反向传播过程中自动更新。除此之外,CP-Tuning还引入了输入文本的Mask,表示为[TMSK],用于同时优化辅助的MLM任务,提升模型在小样本学习场景下的泛化性。CP-Tuning算法的损失函数由两部分组成:
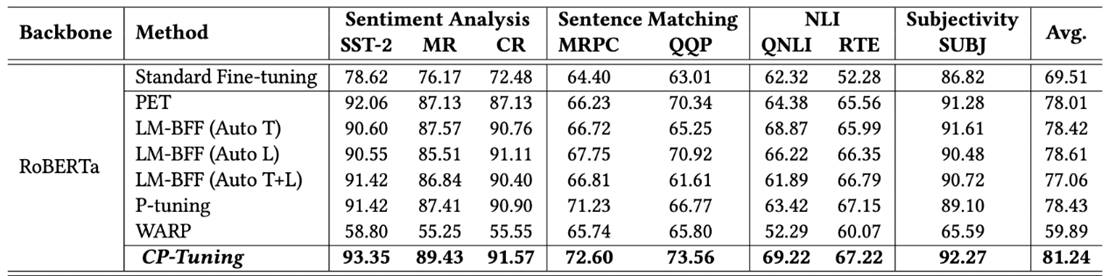
如上所示,两个部分分别为Pair-wise Cost-sensitive Contrastive Loss(PCCL)和辅助的MLM损失。我们在多个GLUE小样本数据集上进行了验证,其中训练集中每个类别限制只有16个标注样本。从下述结果可以看出,CP-Tuning的精确度超越了经典的小样本学习算法,也比标准Fine-tuning算法的精确度高10%以上。
目前,除了我们自研的CP-Tuning算法之外,EasyNLP框架中集成了多种经典小样本学习算法例如PET、P-tuning等。 小样本学习实践详见:https://github.com/alibaba/EasyNLP/tree/master/examples/fewshot_learning 大模型落地实践 下面我们给出一个示例,将一个大的预训练模型(hfl/macbert-large-zh)在小样本场景上落地,并且蒸馏到仅有1/100参数的小模型上。如下图所示,一个大模型(3亿参数)在一个小样本场景上原始的Accuracy为83.8%,通过小样本学习可以提升7%,达到90.6%。同时,如果用一个小模型(3百万参数)跑这个场景的话,效果仅有54.4%,可以把效果提升到71%(提升约17%),inference的时间相比大模型提升了10倍,模型参数仅为原来的1/100。
代码详见:https://github.com/alibaba/EasyNLP/tree/master/examples/landing_large_ptms 应用案例 EasyNLP支撑了阿里巴巴集团内10个BU20多个业务,同时过PAI的产品例如PAI-DLC、PAI-DSW、PAI Designer和PAI-EAS,给集团用户带来高效的从训练到落地的完整体验,同时也支持了云上客户自定定制化模型和解决业务问题的需求。针对公有云用户,对于入门级用户PAI-Designer组件来通过简单调参就可以完成NLP模型训练,对于高级开发者,可以使用AppZoo训练NLP模型,或者使用预置的预训练模型ModelZoo进行finetune,对于资深开发者,提供丰富的API接口,支持用户使用框架进行定制化算法开发,可以使用我们自带的Trainer来提升训练效率,也可以自定义新的Trainer。 下面列举几个典型的案例:
RoadMap
参考文献 [1] [AAAI 22] DKPLM: Decomposable Knowledge-enhanced Pre-trained Language
Model for Natural Language Understanding. https://arxiv.org/abs/2112.01047 [2] [ACL 2021] Meta-KD: A Meta Knowledge Distillation
Framework for Language Model Compression across Domains. https://arxiv.org/abs/2012.01266
[3] [arXiv] Making Pre-trained Language
Models End-to-end Few-shot Learners with Contrastive Prompt Tuning: https://arxiv.org/pdf/2204.00166
[4] [AAAI 22] From Dense to Sparse: Contrastive Pruning
for Better Pre-trained Language Model Compression. https://arxiv.org/abs/2112.07198
[5] [EMNLP 2021] TransPrompt: Towards an Automatic
Transferable Prompting Framework for Few-shot Text Classification. https://aclanthology.org/2021.emnlp-main.221/
[6] [CIKM 2021]. EasyTransfer -- A Simple and Scalable
Deep Transfer Learning Platform for NLP Applications. https://github.com/alibaba/EasyTransfer 开源项目地址:https://github.com/alibaba/EasyNLP
钉钉答疑交流群:33712734 https://www.aliyun.com/activity/bigdata/opensource_bigdata__ai
|
 /1
/1